Creando un cluster de bases de datos tipo active-active usando PostgreSQL
Todos los nodos activos simultáneamente compartiendo la carga de trabajo, habilitando alta disponibilidad y escalabilidad.
Es común encontrar escenarios en los que las empresas necesitan tener la habilidad de leer y escribir datos de manera simultánea en puntos geográficamente dispersos. Muchas veces, esas necesidades pueden traspasar fronteras entre países e inclusive continentes, creando retos tecnológicos que no todos los productos pueden satisfacer de manera satisfactoria.
Esta ha sido una de las principales razones por las cuales los proveedores en la nube se han vuelto tan prominentes, porque tienen la capacidad de proveer este tipo de arquitectura sin que uno se tenga que preocupar por los detalles de implementación, aunque esto por lo general trae un alto costo.
Esta configuración se puede implementar usando infraestructura local (on-premise) o en la nube, lo cual provee una gran flexibilidad pero además, posibilita la reducción de costos al estar basada completamente en software libre.
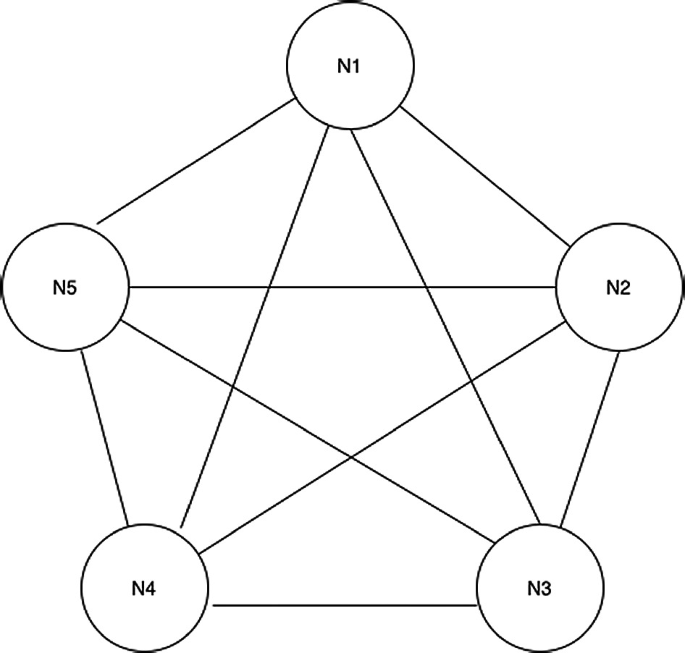
Vamos a similar una red mesh con 5 instancias, vamos a instalar una instancia en 5 namespaces distintos dentro de un mismo cluster de Kubernetes, sin embargo, es importante entender que en un ambiente de producción, se pueden tener estas bases de datos instaladas en diferentes puntos físicos y que no necesariamente tienen que ser el mismo servidor.
Pre-requisitos
Antes de comenzar con la instalación de Microsoft SQL Server 2022 en Kubernetes, es esencial contar con un clúster de Kubernetes funcional. Para ello, te recomendamos seguir los pasos detallados en nuestra: Guía para crear un servidor personal de Kubernetes. Esta guía te proporcionará las instrucciones necesarias para configurar tu entorno de Kubernetes de manera adecuada, asegurando que los siguientes pasos del tutorial se ejecuten sin inconvenientes.
Procedimiento
Vamos a simular 5 nodos distintos utilizando 5 namespaces diferentes en kubernetes. Cada uno de estos nodos va a correr una instancia de PostgreSQL, y cada nodo va a replicar y recibir cambios del resto de los nodos en la red:
Script que crea 5 namespaces e instala postgresql en cada uno de ellos
helm repo add bitnami https://charts.bitnami.com/bitnami helm repo update for i in {1..5} do echo "========= n$i =========" helm install pg$i bitnami/postgresql -n n$i --create-namespace \ --set auth.postgresPassword=postgres \ --set auth.replicationUsername=active_active \ --set auth.replicationPassword=active \ --set architecture=replication \ --set auth.database=db01 \ --set primary.service.type=LoadBalancer \ --set primary.persistence.storageClass=longhorn \ --set primary.persistence.size=1Gi \ --set primary.configuration="wal_level=logical max_replication_slots=10 max_wal_senders=10 max_worker_processes=8 max_logical_replication_workers=4 max_sync_workers_per_subscription=2 listen_addresses='*'" doneCrear una tabla y la publicación en cada nodo
for u in {1..5} do echo "========= pg$u =========" kubectl exec -n n$u pg$u-postgresql-primary-0 -- bash -c " PGPASSWORD=postgres psql -U postgres -d db01 -c \" drop publication if exists pg$u; drop table if exists t1; create table t1( id uuid default gen_random_uuid(), comments text default 'pg$u-example', t_stamp timestamptz default now(), PRIMARY KEY (t_stamp,id) ); grant all on all tables in schema public to active_active; create publication pg$u for table t1; \" " doneCreando la suscripción en todos los nodos
for u in {1..5} do for v in {1..5} do if [ $u -ne $v ] then echo "========= pg$u -> pg$v =========" kubectl exec -n n$u pg$u-postgresql-primary-0 -- bash -c " PGPASSWORD=postgres psql -U postgres -d db01 -c \" CREATE SUBSCRIPTION pg$v CONNECTION 'host=pg$v-postgresql-primary-hl.n$v.svc.cluster.local port=5432 dbname=db01 user=active_active password=active' PUBLICATION pg$v WITH (origin=none, copy_data=false, slot_name=pg$u); \" " fi done done
Pruebas
Para verificar que la replicación está funcionando adecuadamente, vamos a crear una nueva fila en la tabla t1 dentro de cada una de las instancias. Luego, vamos a hacer un select en cada una de las 5 instancias y ambas deberíamos de poder ver todas las 5 filas en cada una de ellas.
Creando una nueva fila en cada una de las 5 instancias. Esto demuestra que es posible escribir en cualquier instancia y que la información va a ser replicada al resto de los nodos:
for u in {1..5} do echo "========= insert into pg$u =========" kubectl exec -n n$u pg$u-postgresql-primary-0 -- bash -c " PGPASSWORD=postgres psql -U postgres -d db01 -c \" INSERT INTO t1 (t_stamp) VALUES (default); \" " doneAhora revisamos los resultados en t1 para cada una de las 5 instancias
for u in {1..5} do echo "========= select pg$u =========" kubectl exec -n n$u pg$u-postgresql-primary-0 -- bash -c " PGPASSWORD=postgres psql -U postgres -d db01 -c \" SELECT * FROM t1; \" " done

Datos adicionales
La clave para que la replicación mesh funcione en postgreSQL es el parámetro origin=none dentro de la definición de la suscripción; este parámetro es el que evita que se ejecute una replicación infinita entre los nodos.
El parámetro origin controla el origen de los datos que van a ser replicados. Cuando una nueva entrada es creada localmente, el origin es none, pero cuando se replica la información, el origin es el nodo en el que se creó la información, por lo que cuando un suscriptor recibe la nueva fila, esta se guarda localmente, y al ver que el origin es diferente a none, no se replica a otros nodos.
Si usted quisiera entender mejor como se ve la información que está siendo replicada, puede revisar la tabla de suscripciones en uno de los nodos:
kubectl exec -n n1 pg1-postgresql-primary-0 -- bash -c "
PGPASSWORD=postgres psql -U postgres -d db01 -c \"
SELECT subname, subenabled, subconninfo, subslotname FROM pg_subscription;
\"
"

Conclusión
PostgreSQL provee mecanismos robustos para crear bases de datos que son capaces de replicar datos transaccionales a múltiples nodos de manera eficiente y confiable.
Este ejemplo puede ser extendido para poder crear esquemas tipo arbol de navidad, para por ejemplo agregar bases de datos que evitan que los reportes conectados a las bases de datos afecten el rendimiento total del sistema.